천만 사용자를 위한 AWS 클라우드 아키텍처 진화하기
천만 사용자를 위한 AWS 클라우드 아키텍처 진화하기 영상을 보고
정리한 포스팅입니다!
포스팅에 첨부된 모든 이미지는 Amazon Web Service Korea에서 업로드한
위 영상 내에 나오는 이미지임을 알립니다~!
천만 사용자를 위한 아키텍처
1,000만명이 사용해도 서비스할 수 있도록 팀의 인프라 아키텍처 개선 방향을 고민한다 (구현 X)
팀 프로젝트 요구사항으로 제시된 문구입니다.
구현은 하지 않아도 되지만, 천만 사용자를 감당할 수 있는 아키텍처에 대해 고민해보라는 것이죠.
최근 카카오의 장애 사례를 겪으면 SPOF를 없애는 것의 중요성을 크게 깨달은 바 있는데요,
천만 사용자를 감당하려면 물리적으로 뛰어난 성능도 중요하지만
SPOF를 없애고, 재난 복구(DR)를 구축하는 것도 중요할 것 같습니다.
천만 사용자를 위한 아키텍처에 대해 혼자 고민해볼 때에는
WS, WAS, DB 등에 대해 이중화를 적용하는 것 이상으로 아이디어가 떠오르지 않았습니다.
관련하여 영상을 찾아보니 AWS에서 같은 제목으로 수년 째 아키텍처에 대한
영상을 발표해오고 있는 것을 확인했습니다.
물론 AWS에서 자사 서비스의 홍보를 목적으로 만든 영상이겠지만,
천만 사용자를 대응할 아이디어를 충분히 얻을 수 있을 것 같아 영상을 시청하고 정리해봤습니다.
이하 내용은 모두 천만 사용자를 위한 아키텍처를
AWS를 사용해 구현한다는 기준에서 작성되었습니다.
100명 이하의 사용자 - 비용 효율적 최초 구성
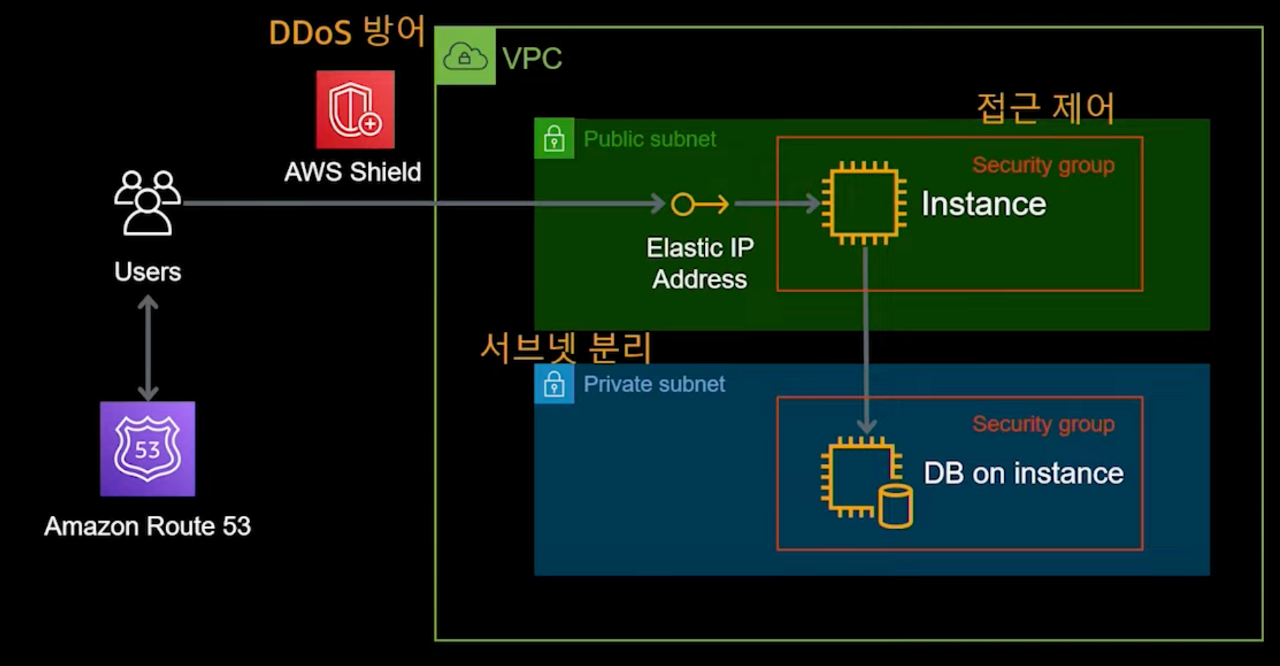
- 초기 개발을 막 마치고 서비스를 시작하는 시점입니다.
- 필요 이상의 성능을 위해 많은 비용을 지출하는 것 보단 비용적 효율성이 중요합니다.
- EC2 : 서비스에 알맞은 적절한 성능의 EC2를 선택하되, 추후 변경도 가능합니다.
- DB : EC2에 DB를 설치해서 사용하되, 서브넷을 나눠 내부에서만 접근가능하게 했습니다.
- Route 53 : AWS에서 제공하는 DNS 서비스입니다.
- Shield : 최소한의 보안을 위해 DDos방어 역할을 수행해줄 서비스입니다.
Route 53, Shield 는 아직 사용해보지 않은 서비스이지만,
여기까지는 아주 익숙한 모델인 것 같습니다.
1,000명 이상의 사용자 - ELB를 이용한 이중화
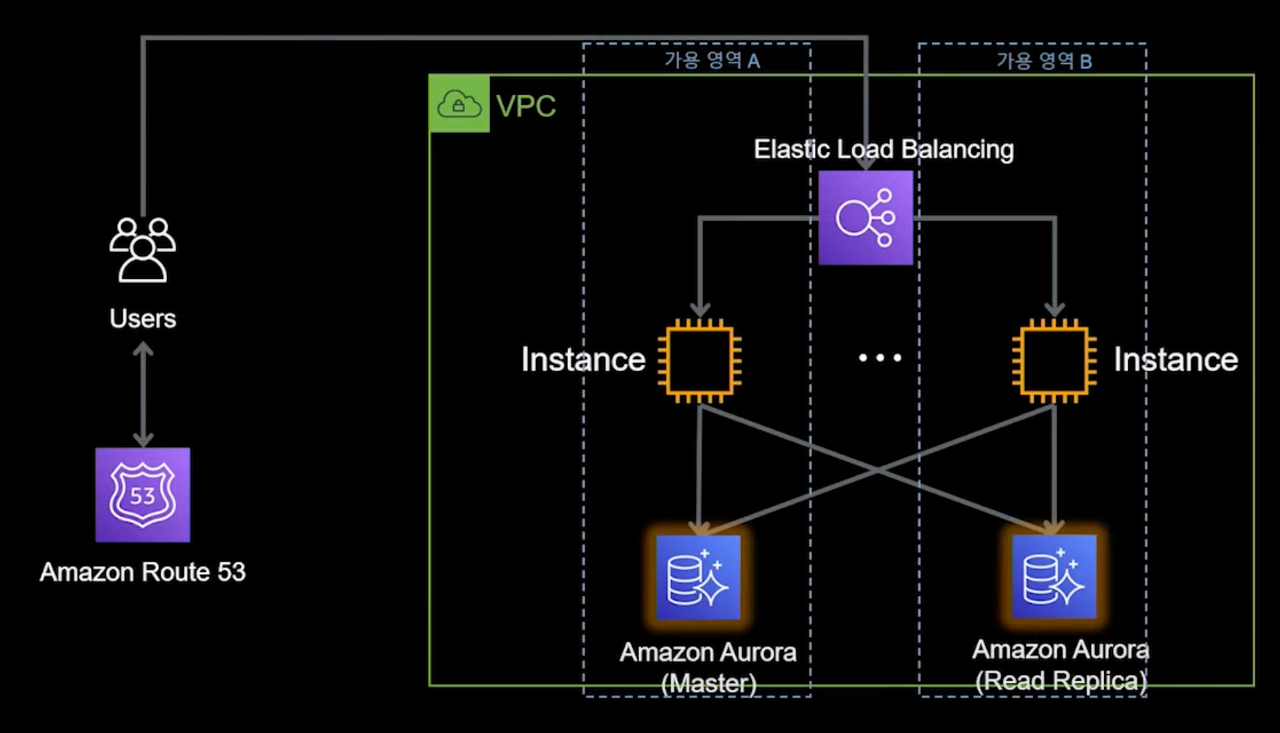
- 트래픽 증가에 대한 대비를 시작해야하는 시점입니다.
- ELB를 이용해 가용영역을 나눠 이중화하였습니다.
- ELB는 AWS에서 제공하는 로드 밸런싱 서비스로, L7기반 ALB와 L4기반 ELB가 있습니다.
- 인스턴스에 설치해 사용하던 DB를 Managed DB로 교체했습니다.
- 읽기/쓰기 를 분리해 성능 및 안정성 개선을 꾀했습니다.
- Aurora DB는 MySQL, PostgreSQL과 호환되는 AWS 가 관리해주는 DB 서비스 입니다.
- 관리 포인트가 줄어들고, 확장성, 가용성, 내구성, 성능이 개선됩니다.
- 내부 튜닝을 통해 보다 높은 성능을 보입니다.
- 최대 15개 복제본 자동 생성, 최대 64TB 자동확장 등이 제공됩니다.
10,000명 이상의 사용자 - Auto Scaling Group, 캐싱
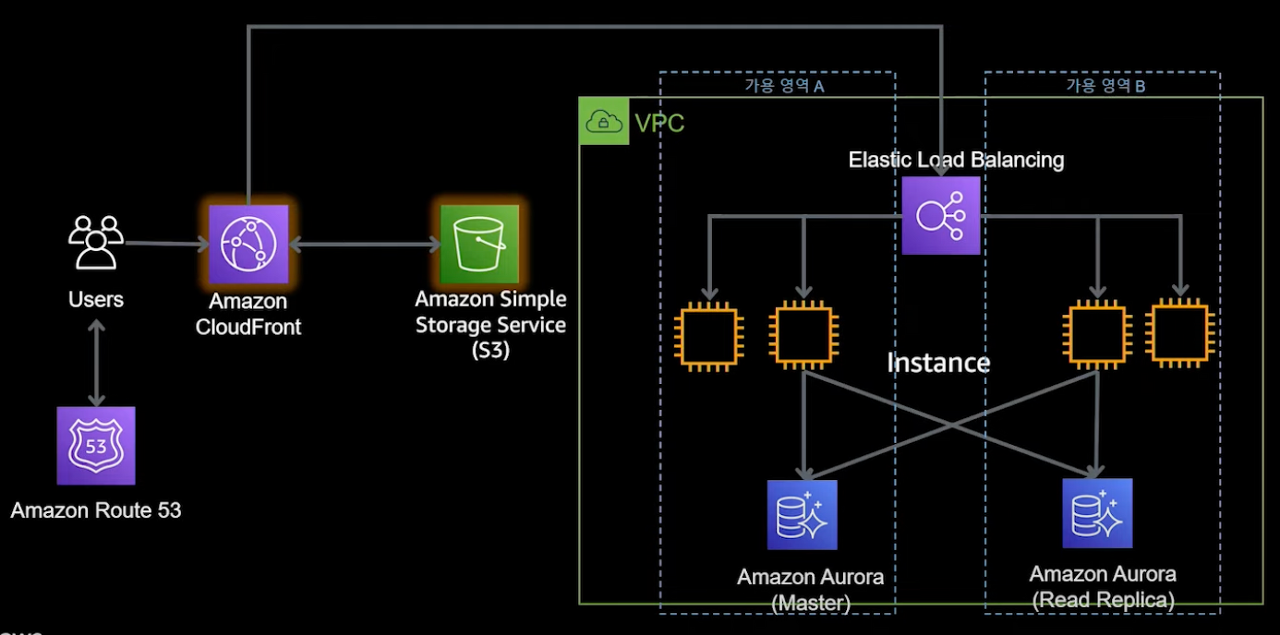
- 본격적으로 성능에 신경써야 할 시기입니다.
- 늘어나는 인스턴스 수에 따라 관리 비용도 증가하기 시작. 자동화를 시작해야 합니다.
- Auto Scaling Group을 이용해 성능, 가용성, 비용, 효율을 모두 챙겼습니다.
- CloudFront, S3를 이용해 정적 리소스 뿐만 아니라 동적 리소스에 대해서도 캐싱을 적용해 성능을 증가시킵니다.
- AWS Systems Manager는 여러 인스턴스들에 대한 관리를 수월하게 할 수 있게 도와줍니다.
- WAF, Shield, GuardDuty 를 이용해 보안을 개선시킵니다.
Auto Scaling Group
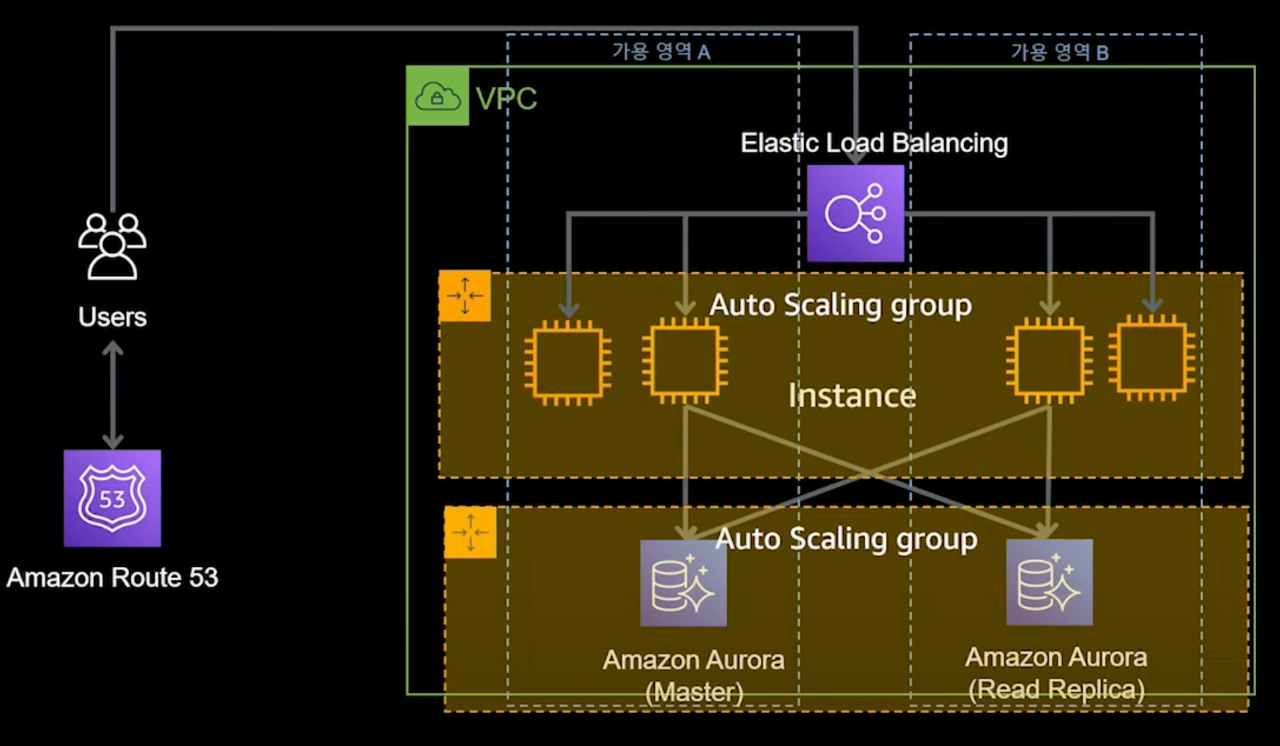
- 온 프레미스 환경이라면 피크 트래픽에 맞춰 리소스를 구성해야 합니다.
- 클라우드 환경에선 오토 스케일링을 통해 최적의 리소스를 자동으로 활용할 수 있습니다.
- AWS 오토 스케일링
- 오토 스케일링 그룹에 쓰레드풀, 커넥션풀 만들듯이 최소 최대값을 설정할 수 있습니다.
- 서버 장애시 최소 수량만큼 자동 복구가 가능합니다.
- CloudWatch 지표 기반 스케일링이 가능합니다.
- 다른 RDS와 AuroraDB는 DB 인스턴스 자체를 오토 스케일링할 수 있습니다.
- 다른 RDS들은 스토리지 용량만 오토 스케일링 가능합니다.
- AuroraDB 인스턴스 CPU 메트릭을 기준으로 오토 스케일링 설정 가능합니다.
100,000명 이상의 사용자 - EKS, Elastic Cache
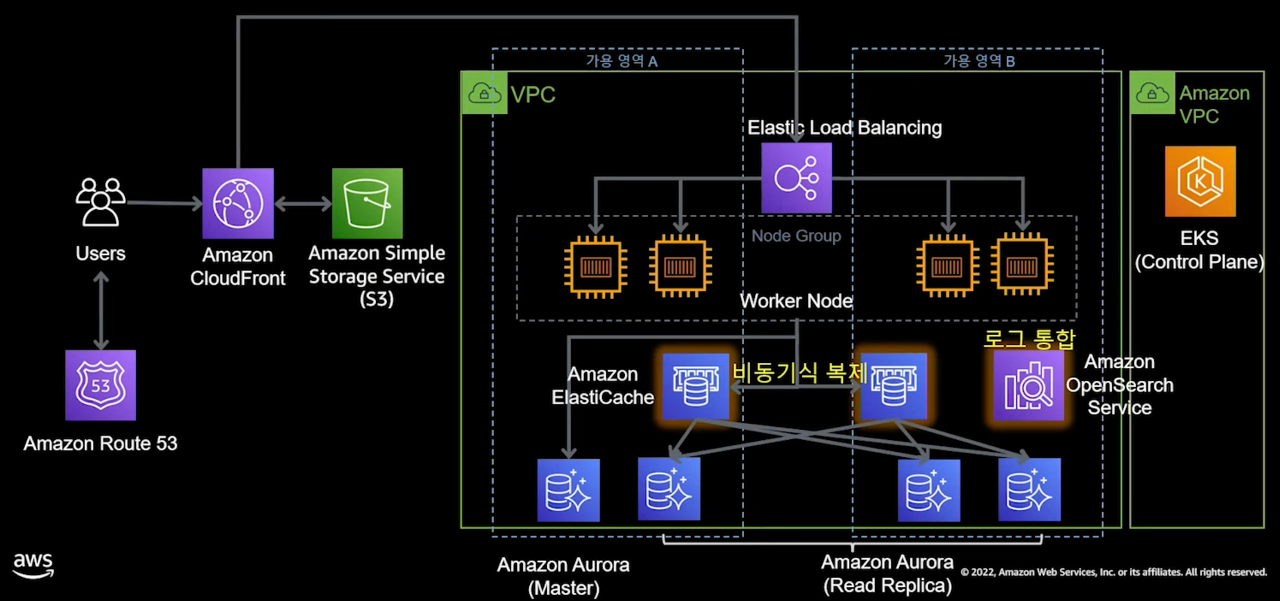
- 러닝 커브로 인해 처음부터 도입하진 않았떤 컨테이너 기반 서비스로 전환을 시작해야 할 시기입니다.
- 컨테이너 기반 서비스는 표준화, 경량화, 이식성, 쉬운 배포로 인해 MSA에서 필수입니다.
- AWS Managed 컨테이너 서비스인 Elastic Kubernetes Service, EKS를 도입했습니다.
- 이제는 배포되는 EC2를 EKS 기반으로 관리합니다.
- DB 읽기 성능 개선을 위해 Elastic Cache를 적용했습니다.
- 쓰기 요청은 Master로 즉시 나갑니다.
- 읽기 요청은 Elastic Cache에서 캐시 미스가 일어날 때에 Replica로 요청이 나갑니다.
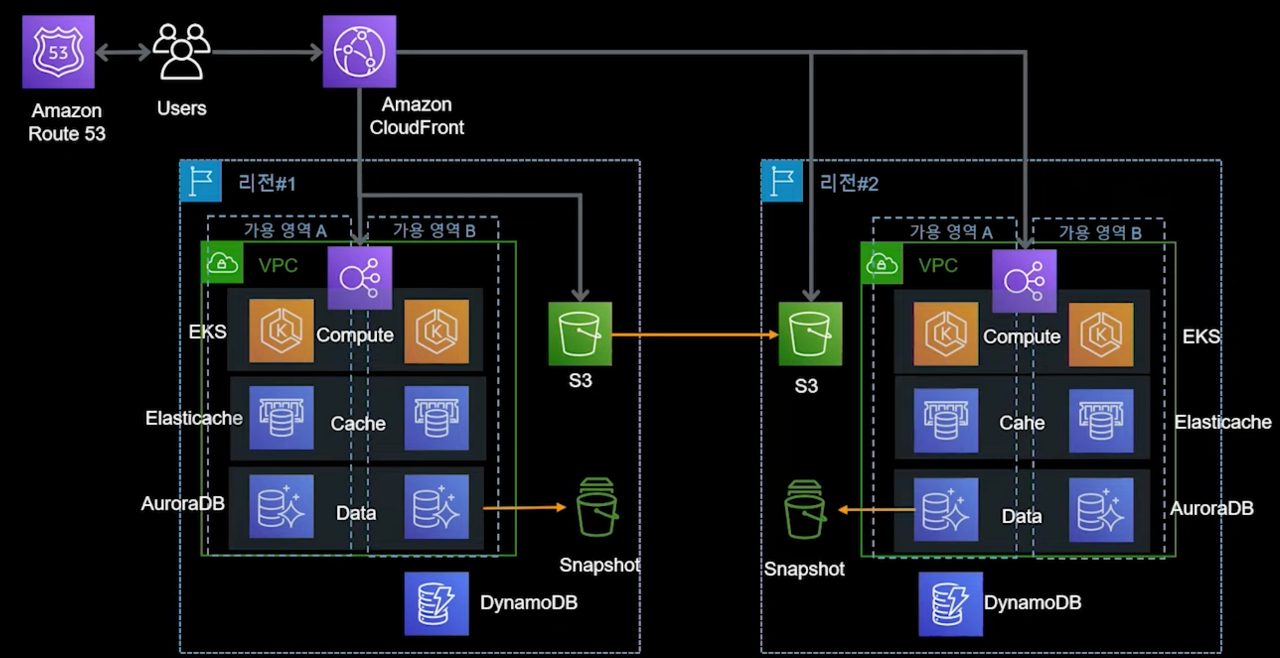
1,000,000만 명 이상의 사용자 - NoSQL 추가, CDK를 이용한 DR 구성
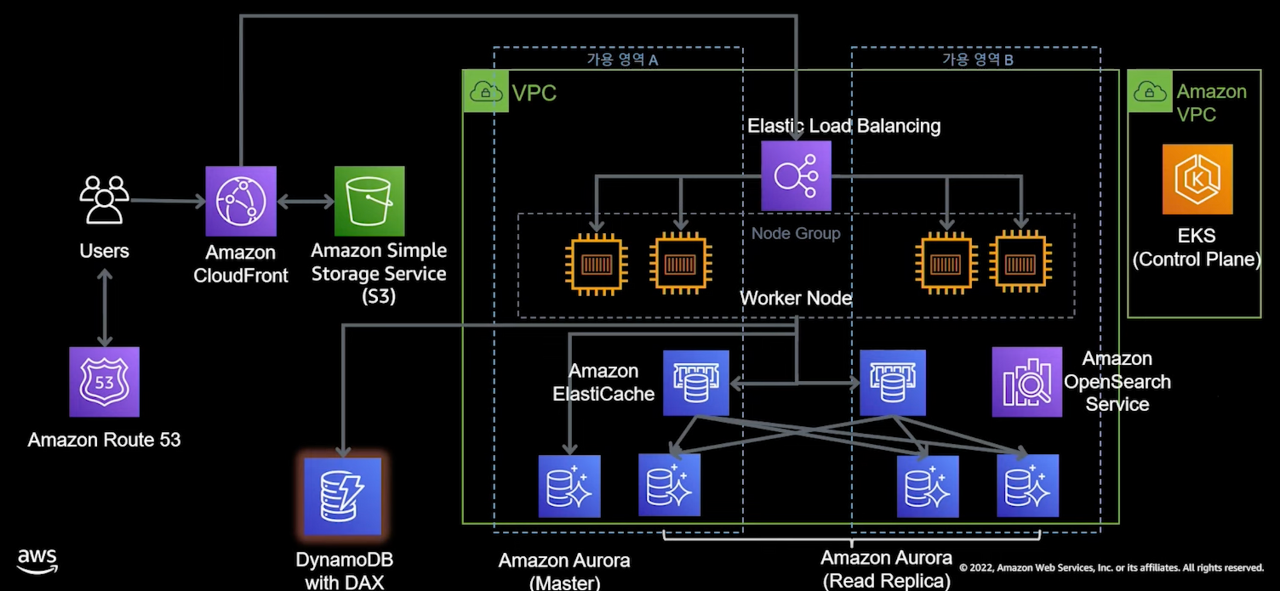
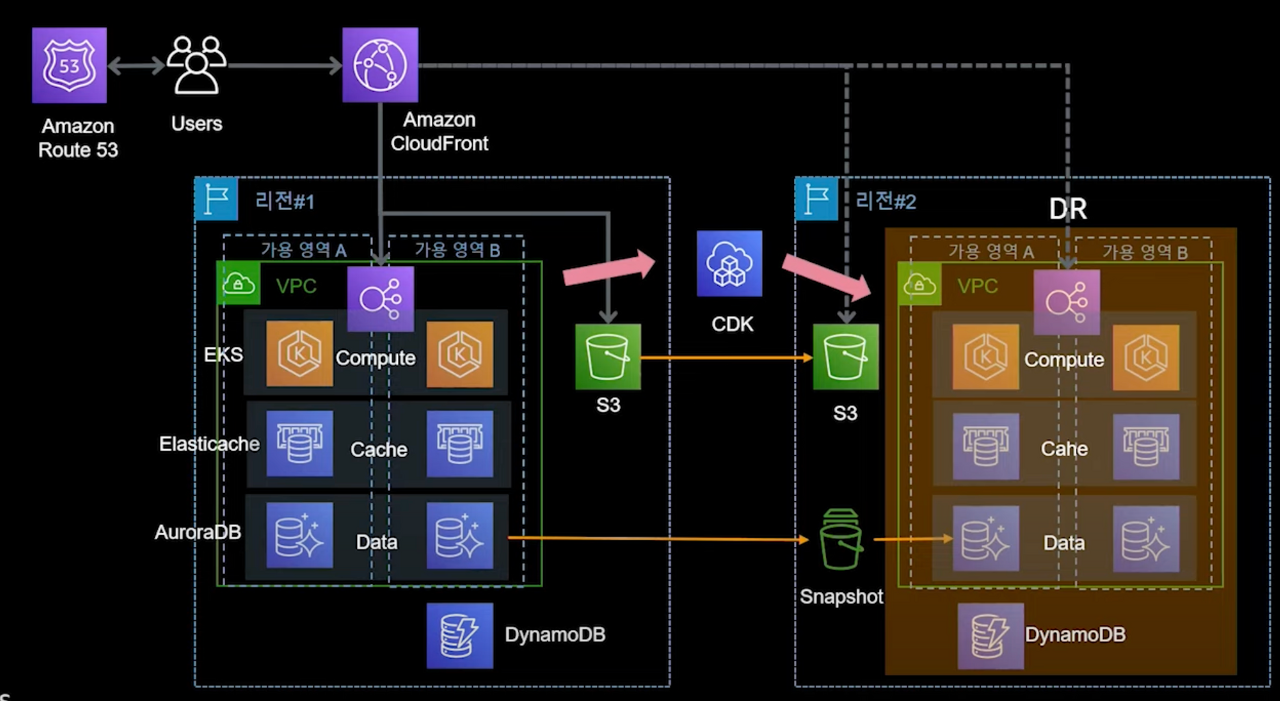
- 기존 구조에서 성능과 가용성을 높이기 위한 노력을 더합니다.
- 쓰기 작업이 빈번하게 일어나는 장바구니와 같은 서비스는 DynamoDB로 분리했습니다.
- DynamoDB는 AWS Managed NoSQL 서비스이며, 대규모 요청에도 한 자릿수 ms 응답시간을 기대할 수 있습니다.
- 아래 이미지에선 CDK 개념이 도입되었습니다.
- Infra as a code를 지향하는 서비스로, 재해복구, DR을 위해 사용됩니다.
- 파이썬, 노드 JS, 타입스크립트, 자바 등의 언어를 사용할 수 있습니다.
- DR 상황에서 복구를 위해 자동화 및 템플릿 생성이 가능합니다.
- 가령 서울 리전에 장애가 발생했을 경우 구성해두었던 CDK로 가까운 다른 리전에 자동 복구되는 것입니다.
- CDK를 통한 인프라 복구시에도 데이터 복구가 동시에 필요합니다.
- S3와 DB에 적재되는 데이터를 예비 리전에 미리 복제시켜두거나 스냅샷을 사용할 수 있습니다.
10,000,000명 이상의 사용자 - 글로벌화
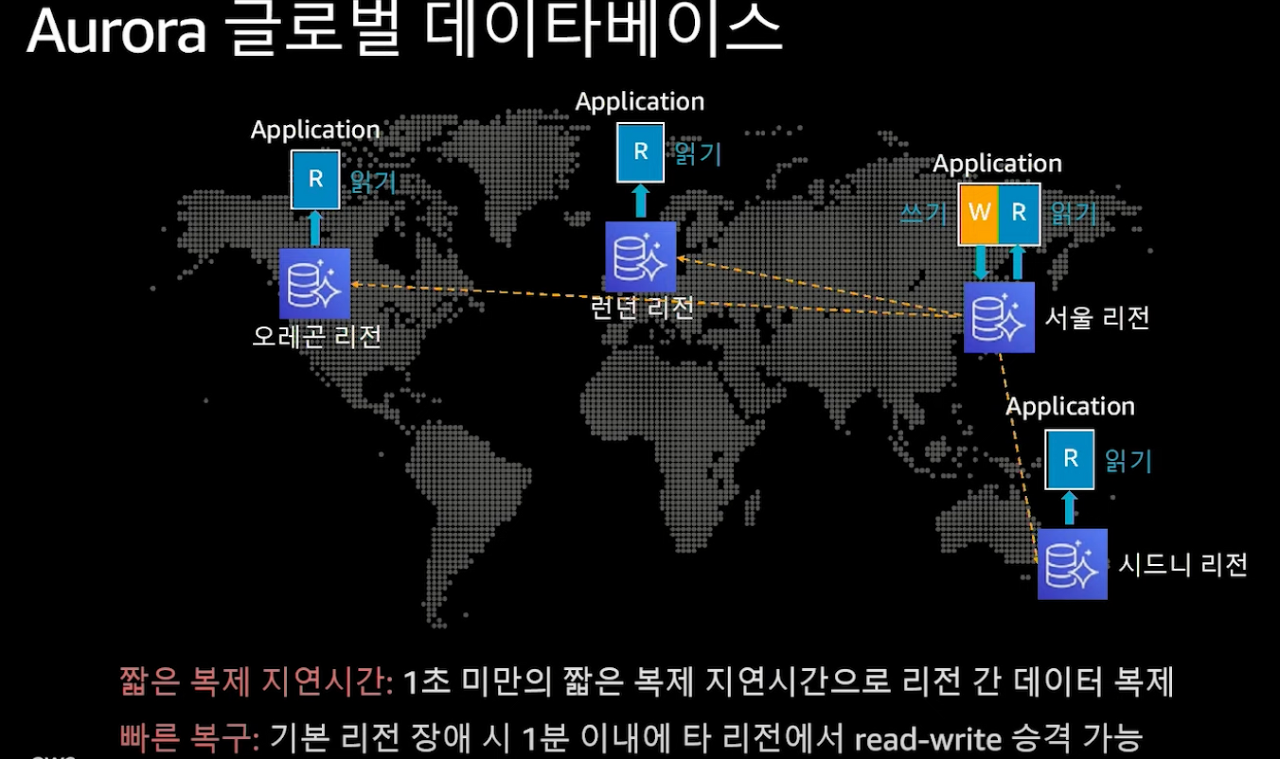
- 기존 구성에서 틀 자체가 달라진다기 보다는 접근성을 높이는 구성입니다.
- Aurora 글로벌 DB를 이용해, 여러 리전에서 읽기 전용을 구성할 수 있습니다.
- 여러 리전에서 더 빠른 응답속도를 제공할 수 있으며, 동기화는 자동으로 처리됩니다.
- Dynamo DB 글로벌 테이블을 이용하면 여러 리전에서 읽기 쓰기가 가능합니다.
- 마찬가지로 변경은 자동으로 전파됩니다.
- 읽기 성능 개선을 위해 사용하던 Elastic Cache 도 글로벌화 가능합니다.
결론
SPOF
SPOF 를 없애기 위해서는 결국 최초 요청을 분배해주는 대상을
우리가 직접 구성하는 것이 아니라 클라우드에 의존하는 컨셉이 가장 주효했던 것 같습니다.
현재 MyRSS 서비스는 인프라 용도로 사용되는 인스턴스에 Nginx를 설치해서
이 Nginx가 모든 요청을 분배하고 있는데요,
해당 인스턴스 혹은 Nginx가 장애를 일으키면 모든 서비스가 마비됩니다.
이를 만약 가용 영역별로 Nginx와 WAS를 구성한뒤,
여러 Nginx를 ELB로 묶어서 분배해준다면 SPOF를 줄일 수 있을 것 같네요.
EKS로 Nginx + WAS를 한 번에 묶어서 Auto Scaling 한다면
더더욱 편리할 것 같습니다.
캐싱
성능 최적화를 위해서는 캐싱 개념이 필수불가결 하네요.
MyRSS에서는 WAS 레벨의 eh 캐시를 우선 적용해보고 있는데요,
WAS 레벨마다 동일한 캐시를 가지고 있게 되면 이 조차 비효율적일 것입니다.
뿐만 아니라 WAS에 장애가 생기면 캐시들이 완전히 무용지물이 되는 것인데요,
만약 CloudFront나 S3를 캐싱레이어로 사용한다면,
일순간 WAS가 장애를 일으키더라도 기존 캐시되어있는 데이터를 제공함으로써
가용성을 높이고 장애 대응 시간을 벌 수 있을 것 같습니다.