
9월 24일 금요일, 모의 면접을 진행할 기회를 갖게 되었습니다.
부족했던 부분을 복기하며 하나씩 채워가고자 합니다.
1. 첫 풀이
완주하지 못한 선수를 IDE 도움 없이 라이브 코딩으로 풀어보는 것이 면접의 시작이었습니다.
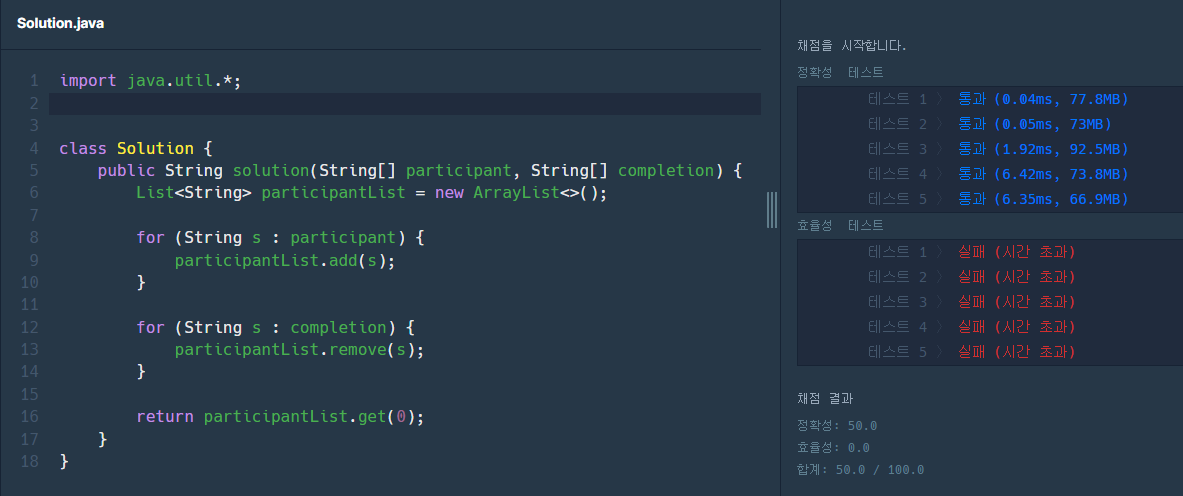
저의 작성 결과는 다음과 같았습니다.
class Solution {
public String solution(String[] participant, String[] completion) {
List<String> participantList = new ArrayList<>();
for (String s : participant) {
participantList.add(s);
}
for (String s : completion) {
participantList.remove(s);
}
return participantList.get(0);
}
}코드를 작성하면서도 말도 안되는 코드라고 느껴서 힘들었습니다.
전혀 효율성이라고는 찾아볼 수가 없는 코드이고 분명 더 나은 방법이 있다고 느껴져셔 였습니다.
그러나 주어진 시간내에 작성을 완료하는 것이 우선이라고 생각되어 일단 작성을 하였습니다.
면접 이후 프로그래머스에 코드를 돌려보니 정확성은 통과하나, 효율성은 통과하지 못하는 코드로 확인됩니다.
2. 답변하지 못한 질문들
코드 작성 완료 이후 시간복잡도가 어떻게 될 것 같은지, 개선할 방법이 있을지에 대해 질문받았습니다.
정확하게는 모르지만, 전체 배열을 순회하며 대상을 찾아 제거하는 작업을 수행하므로 O(n²)이라 생각했습니다.
개선 방법에 대해서는 HashMap을 사용하면 요소 접근이 List순회보다 빨라서 HashMap을 사용하고,
사람 이름을 Key로, 동명이인에 대한 대응으로 Integer를 Value로 하여 처리할 수 있을 것 같은데,
정확히 어찌 구현해야할지는 떠오르지 않는다고 답변하였습니다.
추가적으로 HashMap에 String과 Integer로 10개의 요소를 저장하면 필요한 메모리는 몇 바이트가 될지,
HashMap은 왜 접근속도가 List 보다 빠른지에 대해 질문을 받았고 모두 제대로 답변하지 못했습니다.
문제를 다시 풀어보고, 답변하지 못했던 질문들에 대해 공부한 내용을 포스팅으로 대신해보겠습니다.
3. HashMap을 사용해 시간복잡도를 O(n)으로 개선한 코드
먼저, HashMap을 사용해 개선한 코드입니다.
import java.util.HashMap;
import java.util.Map;
class Solution {
public String solution(String[] participant, String[] completion) {
String answer = "";
// [ 시나리오 ]
// 1. Map<완주자명, 사람수> 에 모든 완주자를 담는다.
// 2. 참가자 배열을 순회하며 참가자명을 Key로 Map<완주자명, 사람수> 에서 get을 시도한다.
// 3-1. 값이 존재할 경우(= Value가 1 이상) Value에서 1을 차감한다.
// 3-2. 값이 존재하지 않을 경우(= Value가 0) 완주하지 못한자로 판정하고 리턴한다.
Map<String, Integer> completedRunners = new HashMap<>();
for (String c : completion) {
completedRunners.put(c, completedRunners.getOrDefault(c, 0) + 1);
}
for (String p : participant) {
boolean isCompletedRunner = completedRunners.getOrDefault(p, 0) > 0;
if(isCompletedRunner) {
completedRunners.put(p, completedRunners.get(p) - 1);
} else {
answer = p;
break;
}
}
return answer;
}
}
먼저 완주자 이름 String을 Key로, 사람 수 Integer를 Value로 하는 HashMap에 모든 완주자를 담았습니다.
Map의 getOrDefault 메소드를 이용해 동명이인의 경우 Value가 1씩 증가하도록 처리하였습니다.
그후, 참가자 명단을 순회하며 참가자가 완주자Map에 존재하는지 확인합니다.
확인 방법은 getOrDefault 메소드로 Value를 가져오는것인데,
이때 가져온 Value가 0이면 이 참가자를 완주하지 못한자로 판정하여 순회를 중단하고 반환합니다.
4. HashMap의 동작 원리와 시간복잡도
기본 개념을 익히기 위해 노마드코더, 자바의정석 영상을 참고하였고,
보다 자세한 내용을 학습하기 위해 알고리즘 대한민국 영상을 참고하였습니다.
요약
1. Hash Table은 배열과 링크드리스트로 이루어진 저장공간입니다.
2. 인덱스를 안다면, O(1)의 시간복잡도로 접근이 가능한 배열의 장점을 사용하여,
빠른 삽입, 삭제, 탐색이 가능합니다.
3. 해시값이 중복되는 충돌 현상에 대한 대응으로 Java에서는 LinkedList를 이용한 Chaining방식을 이용하고 있습니다.
4. Hash의 사전적 의미를 검색해보면 으깨다, 엉망으로 만들다 등의 의미를 찾을 수 있습니다.
영영 사전에서 명사적 의미를 검색하면 정리되지 않은 사실과 숫자의 잡동사니 라는 의미도 발견할 수 있습니다.
고유값을 만들기 위해 기존의 형체를 알아보기 어렵게 만드는 Hash Function의 의미와 통한다고 볼 수 있겠습니다.

HashMap의 동작 원리에 대해 이해한 내용을 토대로 스프레드시트로 내용을 정리해봤습니다.
EntrySets에 있는 Key Value 쌍 4개를 HashMap의 put 메소드로 저장하는 시나리오입니다.
Hash Function은 키값의 첫번째 알파뱃을 기준으로 순서대로 0, 1, 2 ... 를 반환하는 알고리즘으로 가정하겠습니다.
먼저 Ace : Python 이라는 Key Value의 저장요청을 받았을 때,
Hash Function에 Ace를 전달하고, 반환된 0을 인덱스로 하여 Hash Table에 저장합니다.
Brian과 Charlie 도 같은 과정을 거쳐 각각 1과 2의 Index에 저장됩니다.
마지막으로 Chloe를 저장할 때는 충돌(Collision)이 발생하게 됩니다.
Index 2에는 이미 Charlie : JavaScript가 저장되어 있기 때문입니다.
Java에서는 이러한 충돌 이슈를 해소하기 위해 Chaining 방식을 택했고,
그 결과 LinkedList 형태로 값이 저장되게 됩니다.
Hash Function의 결과가 중복될 경우, 같은 Index의 LinkedList 요소에
Key,Value로 이뤄진 노드를 이어붙이는 방식입니다.
다시말해 Chloe : Python은 같은 index 2의 Charlie : JavaScript 노드 뒤에 위치하게 된다는 의미입니다.
결론적으로 HashMap은 사람이 알아볼 수 있는 Key값을,
배열의 index처럼 변환하여 빠른 접근이 가능하도록 구현된 자료구조입니다.
그 결과 get, put, remove, containsKey 등의 메소드는 O(1)의 상수 시간복잡도를 가지게 됩니다.
단, key가 아닌 Value를 이용한 탐색, containsValue 메소드의 경우,
Hash Function을 통해 index를 찾아 직접접근이 불가하기 때문에 O(n)의 시간복잡도를 갖게 됩니다.
덧붙여 get 메소드도 충돌로 인해 모든 요소가 하나의 index를 갖게되는 최악의 경우 O(n)의 시간복잡도를 갖게 되고,
Java 8부터는 이러한 문제를 개선하기 위해 LinkedList가 길어지면 Tree로 구조를 변경합니다.
5. 개선된 코드의 시간복잡도 확인
학습한 내용을 토대로 개선한 코드의 시간 복잡도를 다시 확인해보겠습니다.
주석에 작성한대로, 완주자, 참가자 배열을 순회하는 코드는 각각 O(n),
HashMap의 put, getOrDefault 메소드는 O(1)의 시간복잡도를 갖게됩니다.
따라서 전체 코드의 시간복잡도는 O(n)이 됩니다.
private String solution(String[] participant, String[] completion) {
String answer = "";
Map<String, Integer> completedRunners = new HashMap<>();
// 완주자 배열을 순회하므로 O(n), put메소드는 O(1)
for (String c : completion) {
completedRunners.put(c, completedRunners.getOrDefault(c, 0) + 1);
}
// 참가자 배열을 순회하므로 O(n), getOrDefault, put메소드는 O(1)
for (String p : participant) {
boolean isCompletedRunner = completedRunners.getOrDefault(p, 0) > 0;
if(isCompletedRunner) {
completedRunners.put(p, completedRunners.get(p) - 1);
} else {
answer = p;
break;
}
}
return answer;
}
이로써 기존 O(n²) 에서 O(n)으로 시간복잡도가 개선되었는데,
이를 그래프로 확인하게 되면 얼마나 큰 차이인지 더 크게 다가옵니다.

6. 답변하지 못했던 질문 복기
1. HashMap을 이용해서 O(n)의 시간복잡도를 가지는 코드로 개선할 수 있었습니다.
2. List에 비해 HashMap이 빠른 이유는 Hash Function과 Hash Table에 있습니다.
List는 자료를 순서대로 저장하여 선형 검색을 해야하기 때문에 요소 검색 등에 O(n)이 필요합니다.
HashMap은 Hash Function을 이용해 index를 만들어 저장하기 때문에
추후 요소 검색, 삭제 시에도 index를 이용한 직접 접근이 가능하여 O(1)만 필요합니다.
단, 중복되지 않으면서도 빠른 성능을 내는 Hash Function의 구현과,
충돌 문제애 대한 해소 방법이 HashMap의 성능을 좌우한다고 할 수 있겠습니다.
3. Map<String, Integer> 인스턴스에 10개의 값을 넣었을 때 사용되는 메모리는 구하지 못했습니다.
각각의 Entry는 Key의 타입의 크기 + Value의 타입의 크기를 차지하고,
추가적으로 버켓의 수와 각 버켓에 담긴 엔트리들의 수만큼의 메모리가 필요하다는 것 까지 검색결과로
확인하였으나, 정확한 바이트를 계산하는 방법을 확인하진 못했습니다.
대신 IntelliJ에서 Debugging 중 memory 를 확인하는 방법을 사용해봤습니다.
생성자로 맵을 생성했을때 6바이트, 1개의 요소를 추가했을 때 20바이트,
이후 6바이트씩 늘어나다가 최종적으로 10개의 요소가 추가되었을 때 76바이트된다는 점까지 확인했습니다.

7. 결론 및 후기
Hash와 HashMap에 대해 아주 깊이있게 다루지는 못했음에도 불구하고,
학습하고 정리하는데 많은 시간이 소요되었습니다.
완주하지 못한 선수 문제를 처음 풀 때에는 이 문제가 왜 해시 카테고리인지,
해시가 무엇을 의미하는지도 정확히 몰랐습니다.
아무렇지 않게 사용해왔던 HashMap이 더 나은 성능을 위해
정말 많은 노력이 들어간 자료구조라는 걸 배웠습니다.
다음 포스팅에서는 가비지 컬렉션에 대해 알아보겠습니다.
'Algorithm' 카테고리의 다른 글
| 프로그래머스 소수 찾기 (0) | 2021.05.30 |
|---|---|
| 프로그래머스 월간 코드 챌린지 시즌2 4월 후기 (1) | 2021.04.15 |
| 20201026 코테 복기 : 최댓값 구하기, 두 개 뽑아서 더하기, 스킬트리, HashMap (0) | 2020.10.29 |
| 콜라츠 추측 (프로그래머스, Java, Level1) (0) | 2020.07.07 |
| K번째 수 (프로그래머스, Java, Level1) (0) | 2020.07.07 |