
1. 크롤링 대상이 크롤링을 허용하는지 확인
2. pom.xml 에 jsoup 추가
3. 크롤링을 수행할 java 클래스 작성
4. servlet-context.xml 에 내용 추가
5. 스케쥴링
1. 크롤링 대상 사이트의 크롤링 규정을 살핍니다.
구글을 크롤링 대상으로 삼는다면 최상위 폴더 내의 robots.txt 에 접근해서 확인합니다.
https://www.google.com/robots.txt
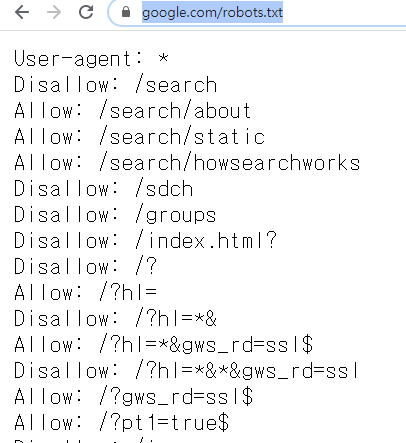
User-agent : * 는 모든 크롤러에게 적용한다는 의미입니다.
Disallow: /search 는 google.com/search 페이지의 크롤링은 금한다는 의미입니다.
Allow:는 반대겠죠?
2. pom.xml 에 jsoup 추가
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
3. 크롤링을 수행할 java 클래스 작성
@Scheduled 어노테이션을 통해서 스케쥴로 등록합니다
(fixedDelay=2000) 밀리세컨 단위로 반복수행할 주기를 설정합니다
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
package crawl;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Crawler {
@Scheduled(fixedDelay=2000)
public void getSpan() {
String url = "https://bit159.ga/a/";
String selector = "a>span";
Document doc = null;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e) {
System.out.println(e.getMessage());
}
Elements titles = doc.select(selector);
for(Element element: titles) {
System.out.println(element.text());
}
}
}
|
cs |
4. servlet-context.xml 에 내용 추가
<beans:bean class="crawl.Crawler" />
<task:annotation-driven />
namespace에서 task 체크
5. 결과 확인



콘솔창에서 동일하게 확인할 수 있습니다
'Java & Spring' 카테고리의 다른 글
| Spring MVC 프로퍼티 파일 value 가져오기 (0) | 2020.09.29 |
|---|---|
| Spring MVC 멀티 파일 업로드 (0) | 2020.09.29 |
| Spring MVC ajax input output 구현시험 (0) | 2020.08.10 |
| Spring Async 스프링 비동기 수행 (0) | 2020.08.07 |
| 2020. 08. 06 (목) 스프링 시큐리티 적용 (3) | 2020.08.07 |