
Reveal2021 - 쿠팡의 대규모 트래픽을 다루는 백앤드 전략 영상을 보고 정리해본 포스팅입니다.
최근 이 영상에서 다룬 문제에 대해 고민하고 있었는데, 너무 멋진 대응 예시를 보게 되어 기쁩니다!
이 영상의 해결방법을 지금 진행중인 프로젝트에 바로 적용하기엔 어렵지만
이러한 접근이 가능하다는 것을 들을 수 있어서 감사했습니다.
많은 데이터를 요구하는 화면

위 예시 이미지에서 보여지는 화면에 필요한 데이터를 구현한다면 어떻게 해야 할까요?
카탈로그, 가격, 혜택가격, 재고 수량, 리뷰 수와 평점, 적립액을 응답해줘야할 겁니다.
그 중에 리뷰와 평점만 살펴본다면 어떨까요?
예시 이미지상 카운트가 4300인데요,
상품 아이디로 리뷰들을 카운팅하고, 갯수로 총점을 나눠서 평점을 구할 수 있겠네요.
카운팅과 평균 계산이라니, DB에서 하던 WAS에서 하던 단순 조회를 넘어서서 무게감이 좀 있을 것 같습니다.
그런데 이러한 컴포넌트가 한 화면에 수십개가 있다면 어떨까요?
수십개의 상품에 대해 리뷰 수를 모두 세서 평점을 계산해서 응답해주려면?
그러한 화면을 이용하는 회원 수가 수백만명이라면 어떨까요?
TPS는 떨어지고, 응답시간은 지연될 것입니다.
서버의 부하가 커졌다는 의미는 트래픽이 많아졌을 때 가용성이 떨어질 가능성이 높다는 의미이기도 하지요.
이런 문제를 어떻게 해결할 수 있을까요?
단순 MSA로 구성한다면?
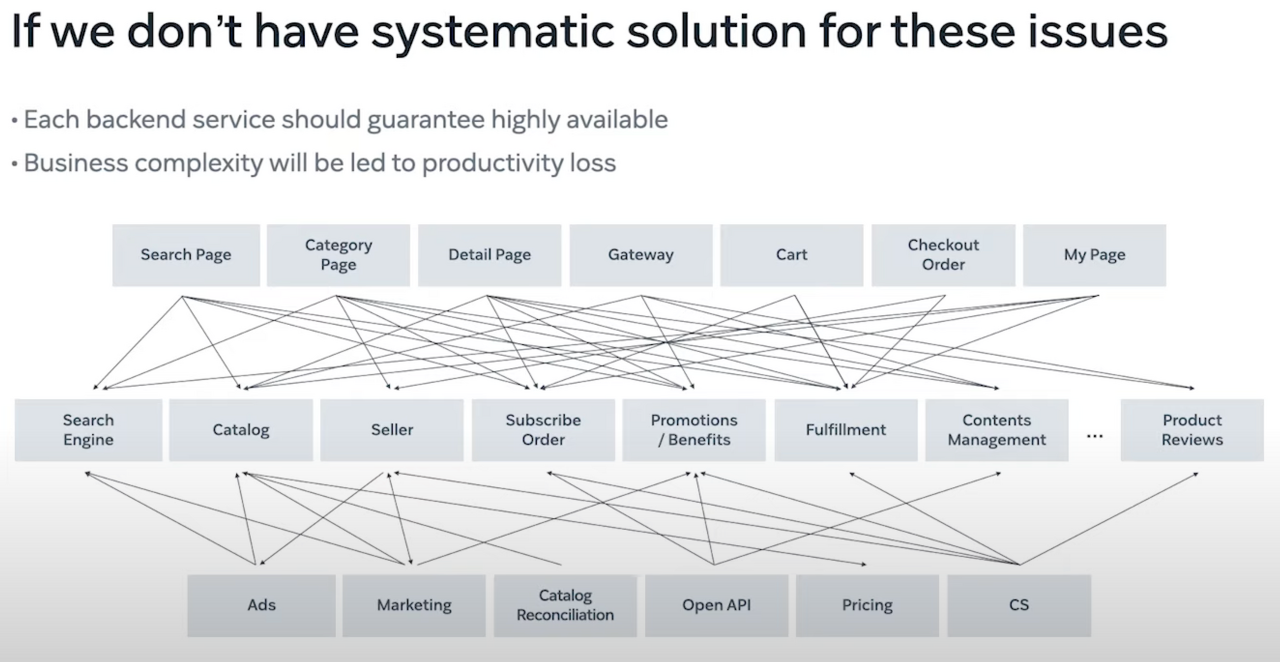
단순 MSA 설계로는 성능적인 측면에 접근하기 이전에 비즈니스 복잡도 조차 풀어내기 어렵습니다.
여러 페이지들이 거미줄처럼 서로 다른 복수의 도메인 자료를 필요로 하고 있기 때문입니다.
또한 하나의 도메인 서버가 다운된다면, 해당 도메인으로부터 데이터를 전달받아 페이지를 구성해야 하는 곳은
모조리 페이지가 다운될 것입니다.
유지보수나 확장에도 아주 불리할 겁니다.
한시가 다르게 급변하는 시장 환경 속에 저 구조가 그대로 유지될 확률이 얼마나 될까요?
수도 없이 많은 도메인이 추가되거나 사라지고 의존관계를 맺고 끊게 될 겁니다.
그때마다 그러한 구조를 모두 파악하고, 유지보수하고 확장해나가기란 상당히 어려울 겁니다.
Reveal2021에서는 쿠팡의 배송 예시를 들고 있습니다.
일반 배송, 로켓 프레시, 쿠팡 배송 등 쿠팡에서는 특별히 배송에까지 다양함이 있어서
비즈니스 로직이 상당히 복잡할 것 같네요.
또한 성능적으로도 불리할겁니다.
하나의 페이지 구성을 위해 여러 도메인에 해당하는 MSA로부터 데이터를 받아 처리해야하기 때문이죠.
커먼 서빙 레이어의 등장
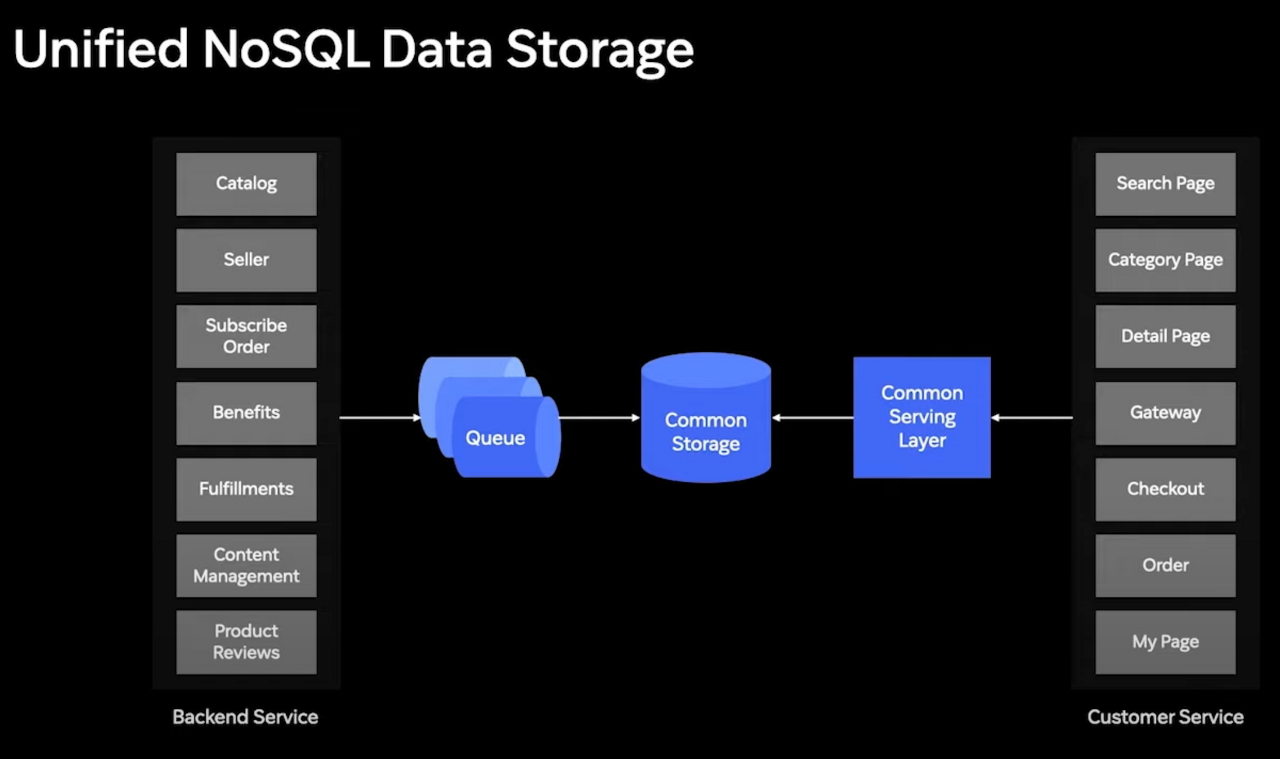

여러 페이지들이 각자 필요로 하는 도메인들을 직접 의존하는 구조에서
커먼 서빙 레이어라는 단 하나의 서버를 의존하는 모습으로 개선되었습니다.
커먼 서빙 레이어는 쿠팡에서 화면 구성에 필요로 하는 모든 데이터와 비즈니스 로직을 서빙합니다.
그러한 데이터는 Common Storage로부터 받아서 서빙하는데요,
이 저장소는 각 개별 도메인에 해당하는 MSA로부터 전달된 데이터가 큐를 통해 적용되어 누적됩니다.
아래의 표를 소비면 카탈로그, 가격, 재고, 리뷰, 할인 정보가 있는데요,
한 행을 하나의 판매 정보로 봤을 때, 이를 여러 컬럼으로 세분화하여 각각 도메인화하여
개발 도메인에서 각각의 컬럼에 해당하는 데이터를 담당하여 한 곳에서 완성되는 식입니다.
가령 1번 아이디에 해당하는 판매 정보에서 가격 변동이 일어난다면,
가격을 담당하는 도메인 MSA에서 가격 변동 정보 처리에 대한 작업을 큐로 전송하고,
이 내용이 Common Storage에 반영될 때 1번 행의 Price가 변경될 겁니다.
마치 개별 도메인 MSA가 커먼 서빙 레이어용 하나의 비 정규화된 커다란 테이블을 구성하는 것이죠.
이렇게 구성하면 쿠팡 내 모든 페이지들은 커먼 서빙 레이어에 요청하여
화면 구성에 필요한 모든 정보를 한 번의 요청으로 받을 수 있게 됩니다.
기존 필요한 개별 도메인에 모두 질의하던 방식에 비해 Read I/O가 상당히 줄어들겠죠?
더 높은 읽기 TPS를 기대할 수 있게 됩니다.
추가로 RDMBS가 아닌 NoSQL을 사용함으로써, Eventual Consistency Model을 선택하여
완전한 실시간성은 아니지만 NRT즉, Near Real Time을 보장합니다.
더 높은 Throughput을 위한 캐시의 도입

각 페이지들은 필요한 데이터를 이미지상 Common Serving Layer에 요청하여 받고 있었고,
Common Serving Layer는 Common Storage를 통해 제공하고 있었습니다.
이 둘 사이에 Cache를 두어서 Throughput을 더 향상시켰습니다.
데이터 저장에 대한 기능은 배제하고 오직 높은 읽기 성능,
즉 높은 TPS와 낮은 응답시간에만 신경쓴 캐시를 둔 것입니다.
쿠팡은 이를 통해 10배 높은 TPS와 1/3수준의 응답시간을 이뤄냈다고 합니다.
다만 주의사항이 있는데요,
Common Storage에 담긴 실제 데이터와 Cache에 있는 데이터가
일치하지 않을 수 있다는 점입니다.
Notification Queue를 통해 캐시 무효화 로직을 구현해
약간의 시차가 발생할 순 있지만 캐시의 성능을 살리면서도
NRT로 최신의 정보를 제공할 수 있게 되었다고 합니다.
하지만 가격이나 배송 정보와 같이 초단위로 적용되어야 하는 정보는 어떨까요?
실시간 데이터용 캐시
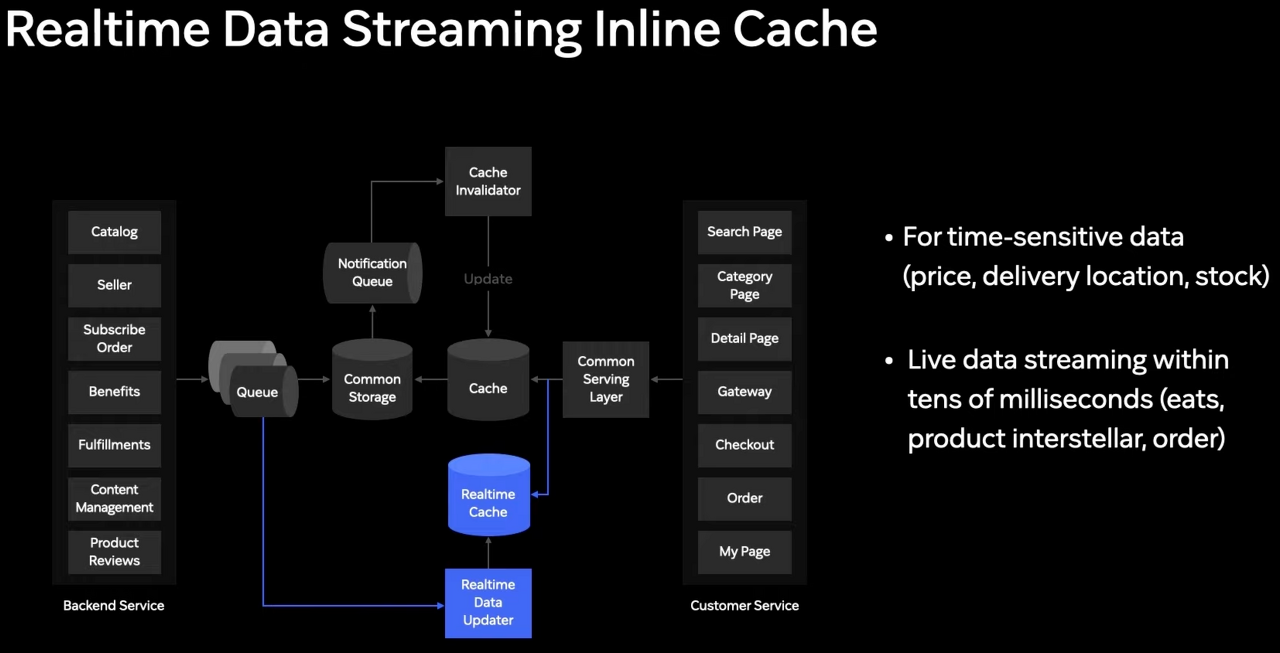
가격, 배송정보와 같이 실시간성 보장이 필요한 데이터들을 윙한 Realtime Cache를 추가로 구축했습니다.
MSA로 구현된 도메인 서버들은 이전처럼 그대로 큐로 변경된 정보를 전송하고,
실시간성이 필요한 정보는 별도의 실시간 캐시에 즉시 적용됩니다.
이제 커먼 서빙 레이어는 두 개의 캐시를 동시에 참조하게 됩니다.
그래서 실시간성 보장이 필요한 정보에 대해서는 둘 중 더 최신의 데이터를 사용하게 됩니다.
이런 구성을 통해 높은 TPS와 낮은 응답시간을 얻을 수 있었습니다.
하지만 더 중요한 가치는 가용성에 있습니다.
높은 가용성을 위한 전략

발표 영상에서는 가용성을 "고객 경험에 영향을 미치는 장애를 최소화하는 것"이라고 정의합니다.
그리고 다음과 같은 사례를 소개합니다.
만약 실시간 캐시 서버가 중단되었을 때, 어느쪽이 고객 경험에 더 낫다고 할 수 있을까요?
A: 상품 상세 페이지가 다운되는 것
B: 실시간 데이터가 반영되지 않은 상품 상세 페이지가 보여지는 것
아마 어렵지 않게 B가 더 나은 고객경험이라고 모두들 선택할 것 같습니다.
따라서 커먼 서빙 레이어는 I/O 지점마다 장애를 고립시켜서 전파되지 않게 해야 합니다.
가령 캐시 서버, 실시간 캐시 서버 모두를 조회해야 하는데,
실시간 캐시 서버가 정상적인 응답을 하지 않는다면
예외를 던져서 조회 자체가 안되게 하는 것이 아니라
캐시 서버에 있는 정보만 가지고서라도 데이터 응답을 해주어야 한다는 것입니다.
이를 위해 쿠팡에선 서킷 브레이커 기술을 적용해
장애가 난 컴포넌트를 고립시키거나, 필요시 수동으로 특정 컴포넌트를 향한 I/O를 중지시킬 수 있다고 합니다.
여기에서 추가로 CSP 라는 개념이 소개되는데요,
CSP는 Critical Serving Path의 약자입니다.
쿠팡 도메인에서 CSP는 주문에 직접적인 영향을 미치는 페이지인데요,
제품 상세 페이지, 주문 페이지 등이 되겠습니다.
이러한 페이지들은 절대 다운되어서는 안되는 중요한 페이지들입니다.
지금까지 소개한 아키텍처를 하나의 클러스터로 삼는다면,
CSP만을 위한 클러스터를 별도로 구성하여, N-CSP와 구별하여
N-CSP 영역의 장애가 CSP 영역으로 전파되지 않게 막는다고 합니다.
아키텍처의 템플릿화

지금까지 고가용성, 높은 TPS, 낮은 응답시간, CSP를 위한 아키텍처 여정을 살펴봤습니다.
바로 판매 상품 정보를 기준으로 말이죠.
그러나 판매 상품 정보 외에도 추가적으로 고가용성, 높은 TPS, 낮은 응답시간이 필요한 도메인이 있을 수 있습니다.
그러한 도메인에도 이러한 아키텍처를 적용하려면 어떻게 해야할까요?
또 그런 도메인이 계속 늘어난다면 어떻게 해야할까요?
커먼 서빙 레이어 아키텍처를 템플릿화 할 수 있습니다.
일부 설정값을 주입받는 템플릿을 만들어서 해당 설정에 따라
해당 도메인의 아키텍처가 바로 적용이 가능하게 만들어두는 것이죠.
소감
우아한테크코스 레벨4 인프라 아키텍처 개선하기를 학습하며
이번 영상이 아주 큰 도움이 되어 정리해봤습니다.
우선 정말 쉽게 잘 설명해주셨구나 라는 생각이 듭니다.
주니어 개발자인 제가 듣기에도 충분히 이해가 잘 되었습니다.
특히, 한 번에 최종 아키텍처를 소개하는 것이 아니라,
단계적으로 이미지, 표와 함께 빌드업해가며 설명을 해주셔서 이해에 큰 도움이 되었습니다.
현재 제작중인 프로젝트에서는 복잡한 여러 도메인 데이터를 필요로 하는 화면은 아직 없어서
커먼 서빙 레이어 아키텍처를 도입할 필요성까진 없지만,
캐시 서버와 큐를 이용한 고가용성, 높은 TPS, 낮은 응답시간에 대해선 도전해봐야할 것 같습니다.
추가로 궁금해지는 지점은 RDBMS가 아닌 NoSQL이
전체 서비스를 지탱하는 데이터 저장소로 사용되는 것인데,
RDBMS와 달리 고려해야할 지점, 장단점등은 어떠한지입니다.
가령 2019년에 전 상품 품절 장애가 발생했을 때,
Redis의 키가 21억개를 넘어서면서 발생한 이슈였다는 이야기를 접한 적 있는데,
만약 Redis를 사용한다면 백업에 대해서, 안정성에 대해서는
어떤식으로 추가 작업이 필요할지 궁금하네요.
사실 이 영상을 통해 Reveal 이라는 쿠팡의 기술 세미나를 처음 접하게 되었는데요,
정말 크게 도움 받았고 쿠팡이라는 회사에 대한 이미지도 훨씬 더 좋아졌습니다 ㅎㅎ
감사합니다 쿠팡, 잘 배웠습니다!
학습 출처
Reveal2021 - 쿠팡의 대규모 트래픽을 다루는 백앤드 전략
'Server & Infra' 카테고리의 다른 글
| 천만 사용자를 위한 AWS 클라우드 아키텍처 진화하기 (0) | 2022.10.24 |
|---|---|
| 확장 가능한 알림 시스템 설계 구상 (2) | 2022.10.07 |
| Apache JMeter를 이용한 부하 테스트 및 리포트 생성 (3) | 2022.10.06 |
| AWS 의도하지 않은 요금 환불받기 (2) | 2022.09.29 |
| AWS CloudWatch 구축기 (EC2를 On-Premise로) (0) | 2022.09.29 |